Kafka2.1.1(CentOS7.6 鲲鹏)
提供Kafka2.1.1基于鲲鹏云服务器预装环境,可在鲲鹏云服务器上一键安装Kafka是一个开源流处理软件平台,用Scala和Java编写。该项目旨在提供统一、高吞吐量、低延迟的平台,用于处理实时数据馈送。它的存储层本质上是一个大规模可扩展设计为分布式事务日志的发布/订阅消息队列。Kafka主要设计目标如下:(1)
商品图片


商品详情
商品亮点
- 鲲鹏兼容:在鲲鹏云服务器正常运行
- 保持原生:基于社区开源组件的官方源码编译安装
- 版本自由:采用稳定的Kafka版本
商品参数
交付方式
镜像
服务监管
如您购买涉及服务监管的商品,您应在购买后进入买家中心提交需求并及时验收
不涉及
开票主体
华为云计算技术有限公司
操作系统
Linux
版本
V2.1.1
上架日期
2019-10-16
所属类别
开发语言环境
商品说明
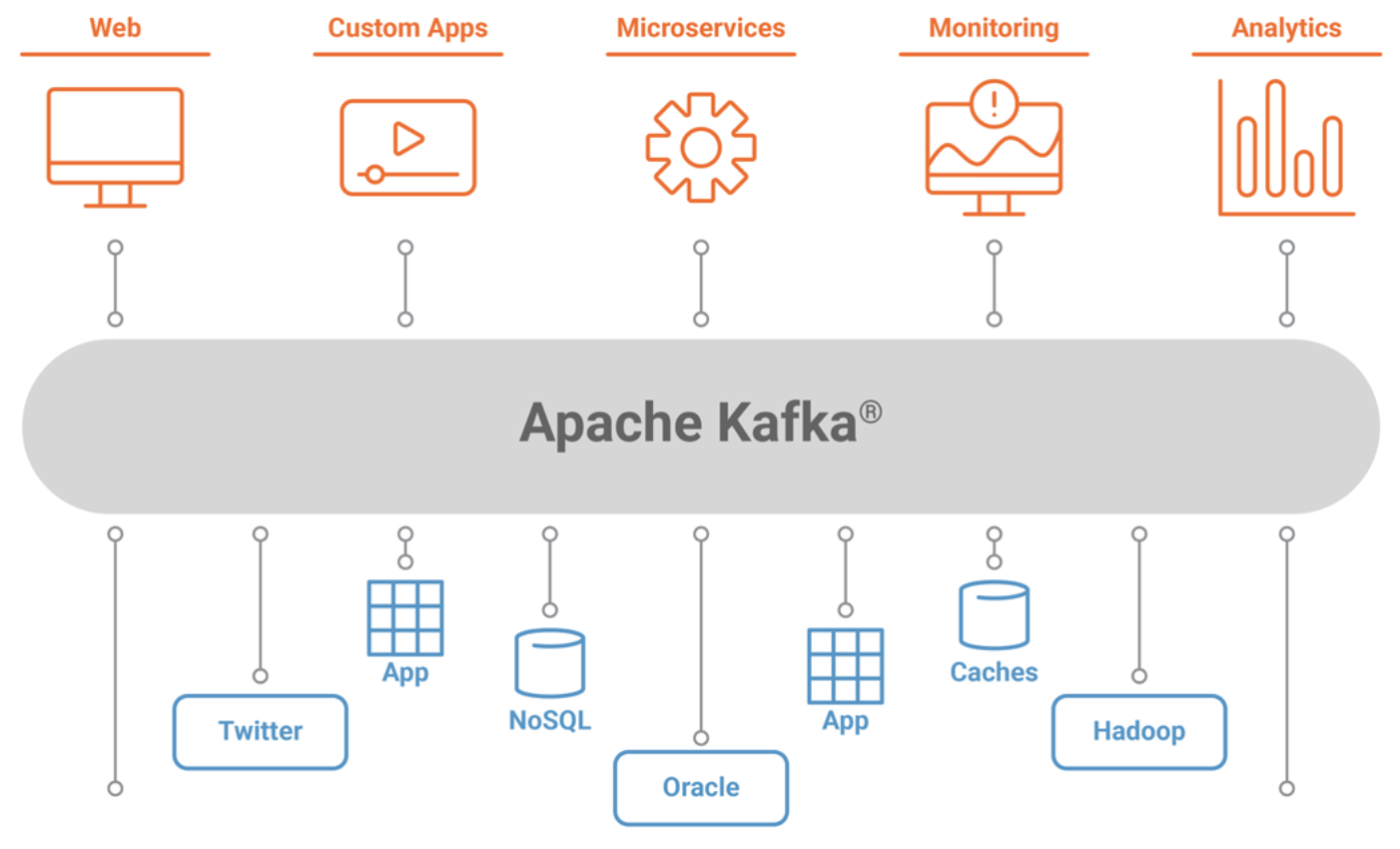
Kafka是一个开源流处理软件平台,用Scala和Java编写。该项目旨在提供统一、高吞吐量、低延迟的平台,用于处理实时数据馈送。它的存储层本质上是一个大规模可扩展设计为分布式事务日志的发布/订阅消息队列。
Kafka主要设计目标如下:
(1) 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
(2) 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
(3) 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
(4) 同时支持离线数据处理和实时数据处理。
(5) Scale out:支持在线水平扩展
Kafka主要特点:
(1) 同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
(2) 可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
(3) 分布式系统,易于向外扩展。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。
(4) 消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
(5) 支持online和offline的场景。
Kafka应用场景:
(1) 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer;
(2) 消息系统:解耦生产者和消费者、缓存消息等;
(3) 用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,亦可保存到数据库;
(4) 运营指标:kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
(5) 流式处理:比如spark streaming和storm。
Kafka主要设计目标如下:
(1) 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
(2) 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
(3) 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
(4) 同时支持离线数据处理和实时数据处理。
(5) Scale out:支持在线水平扩展
Kafka主要特点:
(1) 同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
(2) 可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
(3) 分布式系统,易于向外扩展。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。
(4) 消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
(5) 支持online和offline的场景。
Kafka应用场景:
(1) 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer;
(2) 消息系统:解耦生产者和消费者、缓存消息等;
(3) 用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,亦可保存到数据库;
(4) 运营指标:kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
(5) 流式处理:比如spark streaming和storm。
销售对象
全部用户
商品定价
华北-北京四